Streamline Policy Documentation with Automation and AI

In this third installment of our deep dive, we’re leaping into the future of policy documentation – a journey where automation and AI are the co-pilots. Think about it: In the fast-paced realm of identity and access management, staying on top of policy documentation is like trying to organize a hurricane neatly. It’s vital yet often overwhelming. Well, not anymore! We’re about to change the game by harnessing the power of Okta’s API for extracting policy data, Mermaid for turning that data into understandable diagrams, and a Large Language Model (LLM) for querying this information in a way that feels like having a chat with a wise old sage.
The Case for Automated Documentation
Picture this: piles of policy documents, scattered notes, and a team trying to track changes manually. It’s the old-school way – time-consuming, error-prone, and frankly, a mess. But hey, we’re in an era where technology is our ally, and it’s time we embrace it fully. Automating policy documentation is like having a super-efficient, error-checking robot at your side. It’s about more than saving time (though who doesn’t want more of that?). It’s about accuracy – ensuring that what’s documented reflects the reality in your Okta environment. It’s about consistency – maintaining a single source of truth that doesn’t get lost in translation. And scalability? A breeze. Automated documentation scales elegantly and efficiently, no matter how complex or expansive your environment gets.
Leveraging Okta’s API for Policy Data Retrieval
Now that we’ve set the stage for our tech adventure let’s delve into the treasure trove of Okta’s Policy API. It’s our gateway to accessing a wealth of policy information – a critical step in our journey to streamline policy documentation. Think of Okta’s Policy APIs as a crystal ball, giving us a glimpse into the intricacies of various policy types. Whether it’s the guardrails of Sign-On Policies or the safeguards of Password Policies, each API call brings us closer to understanding and managing our digital ecosystem. Here’s a taste of how this unfolds:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
import os
import sys
import json
import requests
import pandas as pd
from dotenv import load_dotenv
load_dotenv()
okta_api_token = os.getenv("OKTA_API_TOKEN")
okta_org_url = os.getenv("OKTA_ORG_URL")
headers = {
"Accept": "application/json",
"Content-Type": "application/json",
"Authorization": okta_api_token
}
policy_types = ['ACCESS_POLICY', 'IDP_DISCOVERY', 'MFA_ENROLL',
'OKTA_SIGN_ON', 'PASSWORD', 'PROFILE_ENROLLMENT']
## Get all Okta Policies
def fetch_policies_by_type(policy_type):
url = f"{okta_org_url}policies?type={policy_type}"
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.json()
else:
print(f"Error fetching policies of type {policy_type}")
print(response.status_code)
return None
def fetch_all_policies():
policies = []
for policy_type in policy_types:
policies.extend(fetch_policies_by_type(policy_type))
return pd.DataFrame(policies)
df_okta_policies = fetch_all_policies()
Understanding Okta Policy Data Objects and Policy Rules
As we delve deeper into the world of Okta Policy data objects, it’s crucial to understand the policies themselves and the rules governing their resource. Each policy object in Okta is a repository of detailed information, and understanding its structure is vital to effectively transforming this data into visual diagrams and actionable insights.
Attributes of Okta Policy Objects:
- ID: Each policy has a unique identifier. This ID is pivotal for associating policies with their respective rules, ensuring that each rule is applied to the correct policy.
- Type and Name: The type of a policy (e.g., Sign-On, Password, MFA) helps categorize it within the broader security framework. The name provides a descriptive label, making referencing and managing the policy more accessible.
- Conditions and Actions: These attributes define the operational aspects of a policy. Conditions determine the circumstances under which a policy is applied, while actions specify what happens when those conditions are met. They can be complex, often nested with multiple layers, reflecting the nuanced nature of security and access management.
Understanding Policy Rules:
In addition to these attributes, some policies are associated with a set of rules. These rules dictate how policies are enforced and are crucial for fine-tuning policy application in specific scenarios.
- Rule ID: Similar to policies, each rule has a unique ID, essential for linking rules to their respective policies.
- Priority: Rules within a policy have a priority setting, determining the order in which they are evaluated and applied. This hierarchy is crucial in scenarios where multiple rules could apply.
- Conditions (for Rules): The conditions in rules are more specific compared to policy conditions. They can include user groups, network zones, device compliance, and more, providing a granular level of control.
- Actions (for Rules): Actions in rules specify the immediate effects when the rule’s conditions are met. This could involve prompting for MFA, setting session lifetimes, or triggering other security responses.
The synergy between Policies and Rules:
The relationship between policies and their rules is symbiotic. While policies set the overall framework, rules provide the detailed instructions that drive policy enforcement. Understanding these elements is crucial for comprehensively viewing your organization’s security posture. By comprehensively understanding the attributes and relationships of Okta Policy data objects and their rules, we can create more effective visualizations and AI-driven analyses. This holistic view enables us to see and interact with our policy data in more meaningful and impactful ways.
Visualizing Policies with Mermaid
Now comes the artistry with Mermaid. Imagine transforming the complex, multi-layered data from Okta’s API into a visual storyboard. Mermaid lets us depict the flow and structure of our policies in diagrams that are not just informative but also engaging. Here’s how it works:
- Extract and Transform Data: We take our policy data from Okta’s API and reshape it into a format palatable for Mermaid.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
#Create function to fetch rules using the provided rules link
def fetch_rules(rules_link):
response = requests.get(rules_link, headers=headers)
rules = response.json()
return pd.DataFrame(rules)
# Create function to transform rules, conditions, and actions
def transform_rules(rules_df):
conditions_data = []
actions_data = []
for _, rule in rules_df.iterrows():
policy_id = rule['policy_id']
conditions_data.append({'policy_id': policy_id,
'Conditions': rule.get('conditions', {})})
actions_data.append({'policy_id': policy_id,
'Actions': rule.get('actions', {})})
return pd.DataFrame(conditions_data), pd.DataFrame(actions_data)
# Create functions to flatten the conditions and actions dataframes
def flatten_conditions(rule_id, policy_id, conditions):
if conditions is None:
return pd.DataFrame(columns=['rule_id', 'policy_id'])
else:
flattened_conditions = pd.json_normalize(conditions)
flattened_conditions['rule_id'] = rule_id
flattened_conditions['policy_id'] = policy_id
return flattened_conditions
def flatten_actions(rule_id, policy_id, actions):
if actions is None:
return pd.DataFrame(columns=['rule_id', 'policy_id'])
else:
flattened_actions = pd.json_normalize(actions)
flattened_actions['rule_id'] = rule_id
flattened_actions['policy_id'] = policy_id
return flattened_actions
Get Rules and Create dataframes
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
df_rules = pd.DataFrame()
df_rule_conditions = pd.DataFrame()
df_rule_actions = pd.DataFrame()
for _, policy in df_okta_policies.iterrows():
rules_link = policy['_links']['rules']['href']
policy_rules_df = fetch_rules(rules_link)
policy_rules_df['policy_id'] = policy['id'] # Adding policy_id as foreign key
for _, rule in policy_rules_df.iterrows():
try:
conditions_data = flatten_conditions(rule['id'], policy['id'],
rule['conditions'])
actions_data = flatten_actions(rule['id'], policy['id'],
rule['actions'])
except Exception as e:
print(f"Error: {type(e).__name__}")
if str(e):
print(f"Error message: {e}")
# Concatenate data to the respective DataFrame
df_rule_conditions = pd.concat([df_rule_conditions,
conditions_data], ignore_index=True)
df_rule_actions = pd.concat([df_rule_actions,
actions_data], ignore_index=True)
df_rules = pd.concat([df_rules, policy_rules_df], ignore_index=True)
Format and Check data
1
2
3
4
5
6
7
8
# Rename columns to allow the llms to play nicely
df_okta_policies.rename(columns={'id': 'policy_id', 'name': 'policy_name',
'status': 'policy_status',
'type': 'policy_type', 'conditions': 'policy_conditions'},
inplace=True)
df_okta_policies.head()
Output

- Create Visual Representations: Using Mermaid, we translate this data into diagrams, turning rows of text into a visual map of our policy landscape. This isn’t just about making things look pretty. It’s about clarity. It’s about taking the complexity of policies and presenting it in a way that’s intuitive and accessible.
Preparation
Renaming our columns for consistency and adding policy and rule ids where applicable, making it easier for the robots discovery associations between the dataframes.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# Rename our columns for consistency
df_rules.rename(columns={'id': 'rule_id', 'type': 'policy_type',
'conditions': 'rule_conditions', 'actions': 'rule_actions',
'name': 'rule_name', 'status': 'rule_status'}, inplace=True)
## add rule_name and policy_name to df_rule_conditions dataframe
df_rule_conditions = pd.merge(df_rule_conditions,
df_rules[['rule_id', 'rule_name']],
on='rule_id', how='left')
df_rule_conditions = pd.merge(df_rule_conditions,
df_okta_policies[['policy_id', 'policy_name']],
on='policy_id', how='left')
# add rule_name and policy_name to df_rule_actions dataframe
df_rule_actions = pd.merge(df_rule_actions,
df_rules[['rule_id', 'rule_name']],
on='rule_id', how='left')
df_rule_actions = pd.merge(df_rule_actions,
df_okta_policies[['policy_id', 'policy_name']],
on='policy_id', how='left')
Get Application Access Policies
For the scope of my experiment we will focus on the access policies associated to our applications.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# Get the applications linked to a policy using the Okta API
# Example: https://{yourOktaDomain}/api/v1/policies/{policyId}/mappings
# Create a dataset with the Access Policy Type
df_access_policies = df_okta_policies[df_okta_policies['policy_type'] == 'ACCESS_POLICY']
# Iterate through each policy and create a dataset with the application
# and policy context
df_okta_applications = pd.DataFrame()
for _, policy in df_access_policies.iterrows():
policy_id = policy['policy_id']
url = f"{okta_org_url}policies/{policy_id}/mappings"
response = requests.get(url, headers=headers)
if response.status_code == 200:
applications = response.json()
for application in applications:
application['policy_id'] = policy_id
df_okta_applications = pd.concat([df_okta_applications,
pd.DataFrame(applications)],
ignore_index=True)
else:
print(f"Error fetching applications for policy {policy_id}")
print(response.status_code)
df_okta_applications.head()

Add the Application Name
I do not know about you but I prefer to reference my applications using the Label assigned vs an ID, and while we are at it. Let us add the associated policy id. Doing this will help associate an application to a policy.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# Create a function to get the label details of an application
def extract_application_name(links):
response = requests.get(links['application']['href'], headers=headers)
if response.status_code == 200:
application = response.json()
return application['label']
else:
print(f"Error fetching application")
print(response.status_code)
return None
df_okta_applications['application_name'] = df_okta_applications['_links'].apply(extract_application_name)
# Add Policy Name and ID content to the application dataframe
df_okta_applications = pd.merge(df_okta_applications,
df_okta_policies[['policy_id', 'policy_name']],
on='policy_id', how='left')
df_okta_applications.head()

Parsing Constraints
To account for the numerous combinations of possible contraints. We created a function to handle this separately.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
# Helper function to safely parse JSON strings in DataFrame
def safe_json_loads(s):
try:
return json.loads(s)
except ValueError:
return None
# Create a function to parse constraints
def parse_constraints(constraints):
if not isinstance(constraints, list) or not constraints:
return "None"
readable_constraints = []
for constraint in constraints:
parts = []
for factor_class, details in constraint.items():
detail_parts = [f"{key}: {', '.join(value) if isinstance(value, list) else value}"
for key, value in details.items()]
parts.append(f"{factor_class.capitalize()}({' ; '.join(detail_parts)})")
readable_constraints.append(' & '.join(parts))
# Remove any parentheses from the constraints string value
readable_constraints = [constraint.replace('(', ' ').replace(')', '') for constraint in readable_constraints]
return ' OR '.join(readable_constraints)
# GEt a function to get constraints from a series
def get_constraints(constraints_series):
constraints_values = "None"
# After dropna, check if the series is empty
non_null_constraints = constraints_series.dropna()
if not non_null_constraints.empty:
# Extract the first non-null constraint
constraints_data = non_null_constraints.iloc[0]
# Check if constraints_data is a string and parse it
if isinstance(constraints_data, str):
constraints_json = safe_json_loads(constraints_data)
elif pd.notna(constraints_data):
constraints_json = constraints_data # If already a list/dict
else:
constraints_json = None
# Generate constraints description
if constraints_json:
constraints_values = parse_constraints(constraints_json)
return constraints_values
Creation of Mermaid Diagrams and Export Functions
This is where the magic happen and where you can focus on efforts on extracting the data that is important to you. We also using mermaid classes to apply a red or green fill color on a rule depending of if the policy rule is permitting access or denying it.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
# Function which uses the dataframes to generate mermaid diagrams for each policy
def generate_md(policy, rules_df, actions_df, conditions_df):
policy_id = policy['policy_id']
policy_name = policy['policy_name']
# Format the 'Created' and 'Last Updated' dates
created_date = datetime.strptime(policy['created'], '%Y-%m-%dT%H:%M:%S.%fZ').strftime('%Y-%m-%d')
last_updated_date = datetime.strptime(policy['lastUpdated'], '%Y-%m-%dT%H:%M:%S.%fZ').strftime('%Y-%m-%d')
# Filter the rules DataFrame to get only the rules for the current policy
rules = rules_df[rules_df['policy_id'] == policy_id]
md_content = f"""
```mermaid
graph LR
classDef DENY fill:#B80F0A,stroke:#333,stroke-width:1px;
classDef ALLOW fill:#0B6623,stroke:#333,stroke-width:1px;
classDef POLICY fill:grey,stroke:#333,stroke-width:1px;
%%Policy%%
{policy_id}("Policy:{policy_name}"
Policy id: {policy_id}\n
Created:{policy['created']}
Last Updated:{policy['lastUpdated']}
System Policy:{policy['system']}
)
"""
for _, rule in rules.iterrows():
rule_id = rule['rule_id']
rule_name = rule['rule_name']
rule_permission = 'DENY' if rule['rule_actions']['appSignOn']['access'] == 'DENY' else 'ALLOW'
rule_status = rule['rule_status']
# Filter the actions and conditions DataFrames to get only the actions and conditions for the current rule
actions = actions_df[actions_df['rule_id'] == rule_id]
conditions = conditions_df[conditions_df['rule_id'] == rule_id]
if conditions.empty:
platform_type = 'Any'
platform_os = 'Any'
risk_level = 'Any'
else:
# Replace NaN values with 'ANY'
platform_type = 'ANY' if pd.isna(conditions['platform.include']).any() else conditions['platform.include'].iloc[0][0].get('type', 'Any')
platform_os = 'ANY' if pd.isna(conditions['platform.include']).any() else conditions['platform.include'].iloc[0][0]['os'].get('type', 'Any')
risk_level = conditions['riskScore.level'].iloc[0]
constraints_values = get_constraints(actions_df[actions_df['rule_id'] == rule_id]['appSignOn.verificationMethod.constraints'])
factor_mode = actions['appSignOn.verificationMethod.factorMode'].iloc[0]
group_ids = conditions['people.groups.include']
# Flatten the list of lists into a single list
flat_group_ids = [item for sublist in group_ids if isinstance(sublist, list) for item in sublist]
# Join the group IDs into a string
group_ids_str = ', '.join(flat_group_ids) if flat_group_ids else 'Any'
md_content += f"""
%%Rules%%
{rule_id}["Rule:{rule_name}"
Rule id: {rule_id}\n
Created:{created_date}
Last Updated:{last_updated_date}
Status:{rule['rule_status']}
Priority: {rule['priority']}
System Rule: {rule['system']}<br>
Conditions
Group: {group_ids_str}
Access: {rule_permission}
Platform Type: {platform_type}
Platform OS: {platform_os}
Risk Score Level: {risk_level}
"""
if rule_permission == 'ALLOW':
md_content += f"""
Action
Factor Mode: {factor_mode}
Constraints: {constraints_values}
"""
md_content += f"""
]
{policy_id} --> {rule_id}:::{rule_permission}
"""
md_content += "```"
return md_content
# Creates a file using the markdown file extension
def write_to_file(policy_name, md_content):
with open(f"{policy_name}_documentation.md", 'w') as f:
f.write(md_content)
Let it Rip
Now we have all the pieces in play let us write a couple more lines of code to automate the drawing of our application access policies.
1
2
3
4
5
6
7
8
9
10
# Dataframe that contains only Access Policies
df_access_policies = df_okta_policies[df_okta_policies['policy_type'] == 'ACCESS_POLICY']
for _, policy in df_access_policies.iterrows():
file_name = policy['policy_name'] + "_doc.md"
file_path = os.path.join('policy_docs', file_name)
md_content = generate_md(policy, df_rules, df_rule_actions, df_rule_conditions)
write_to_file(file_path, md_content)
Results
Examaple 1
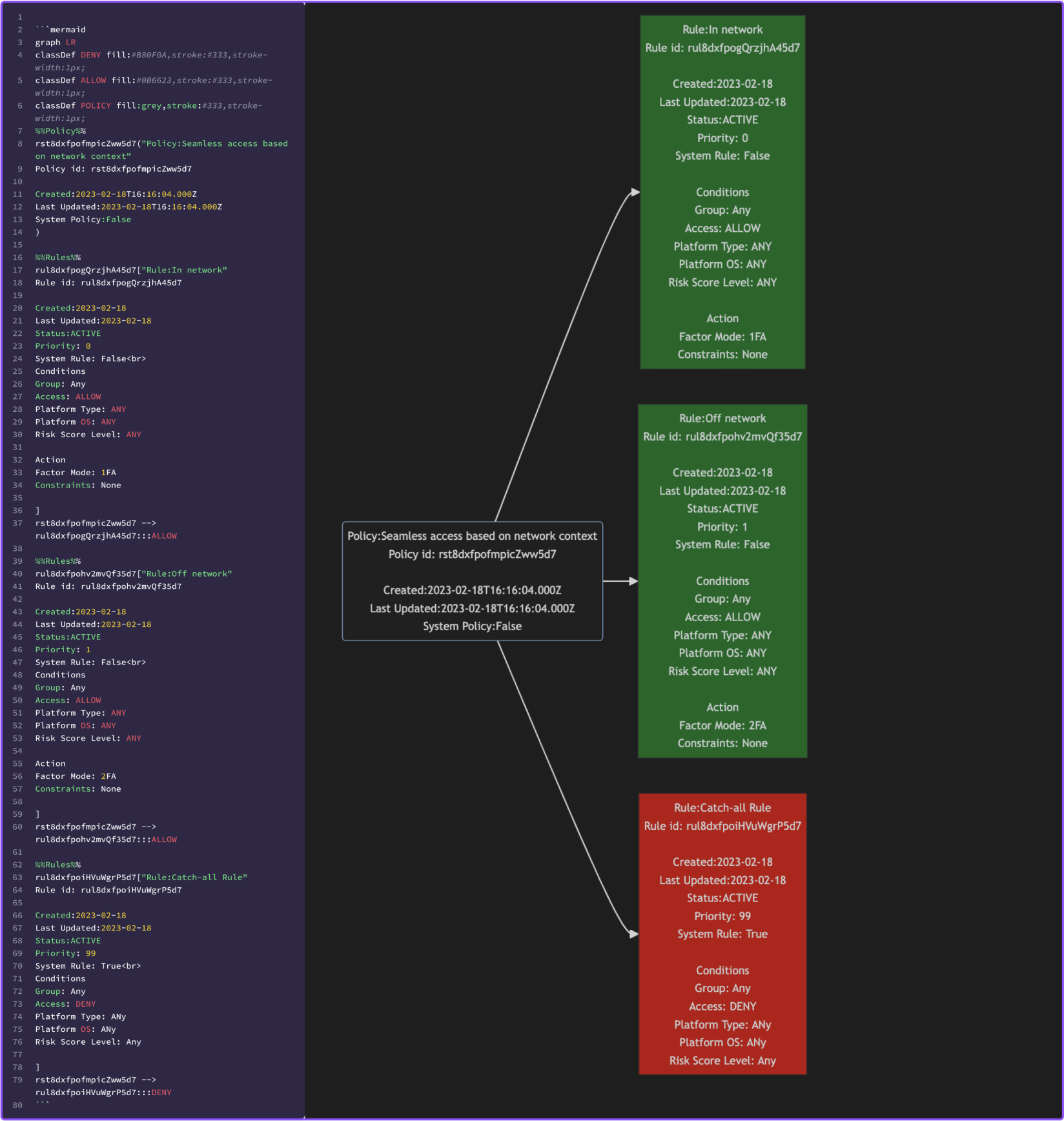
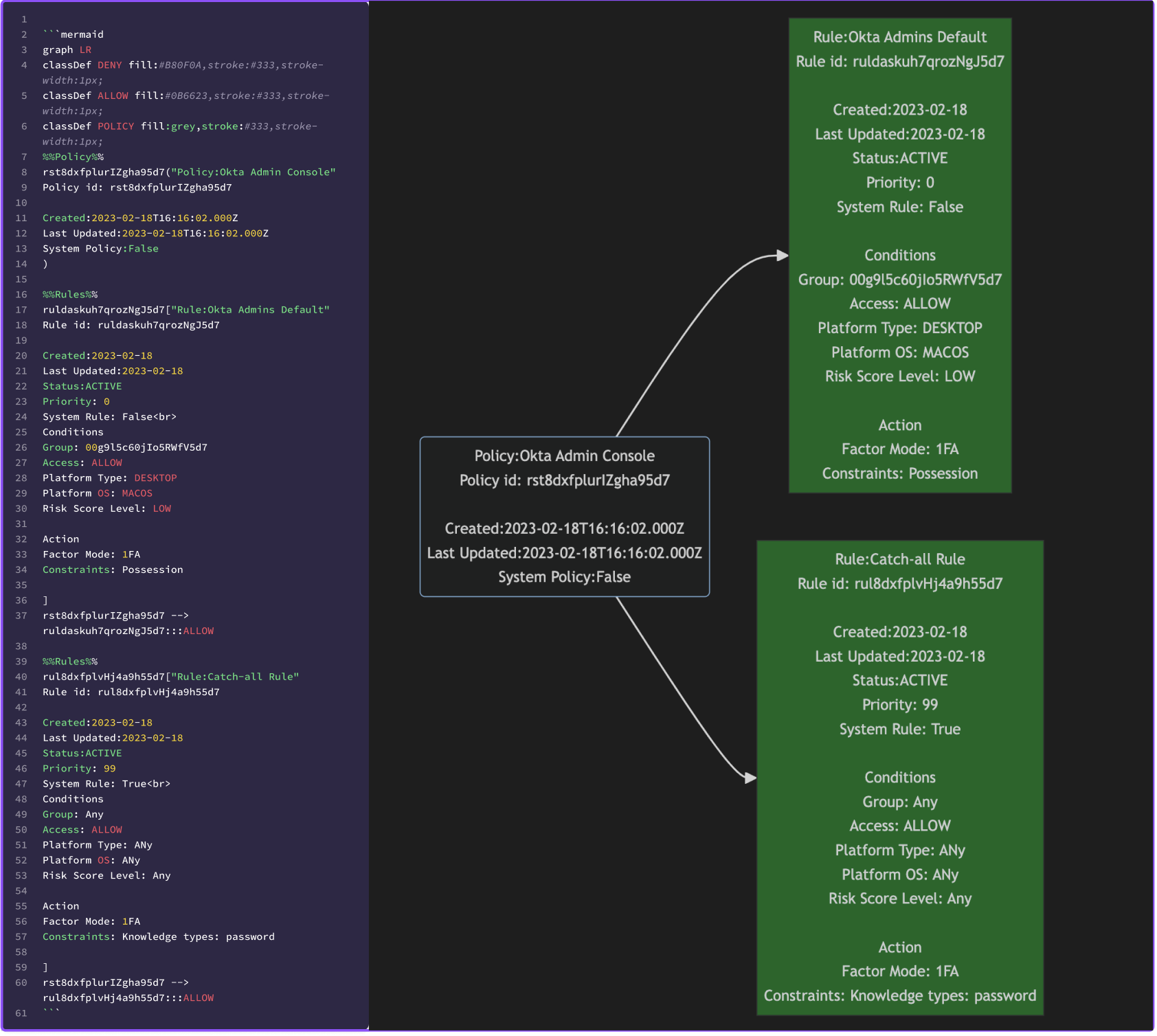
Example 2

Example 3
Enhancing Understanding with Large Language Models
As we delve deeper into the universe of Okta policy management, it’s time to introduce a groundbreaking collaborator in our data odyssey – the Large Language Model (LLM). Imagine this as turning a complex spreadsheet into a conversational partner. LLMs, with their advanced natural language processing capabilities, offer us a way to interact with our complex policy datasets as though we were chatting with a colleague. Picture an LLM as your personal policy advisor, equipped to handle the intricacies of Okta’s policy data easily.
Practical Guide: From Mermaid Visualization to AI-Enhanced Analysis
Now, let’s connect the dots from our earlier Mermaid visualizations to querying with an LLM. We already have our policy data elegantly laid out in visual diagrams and structured DataFrames. The next step is to breathe life into this data with the power of AI.
Set up our Environment
After playing around with some other options, PandaAI library was clearly the best tool for us to use. It allows us to load multiple datasets and provides a flag that ensure we keep our data private.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# Setup environment for us to use LLMs
# We can add this to or set up environment earlier in our project.
from openai import OpenAI
from pandasai import SmartDataframe
from pandasai.llm import OpenAI
from pandasai import SmartDatalake
# For our experiment will be using OpenAI Models
# You can specify your own model here.
# Refer to Pandas AI documentation for a list of supported models
llm = OpenAI(api_token=openai_api_token, org=openai_api_org)
# Pandas AI is basically an LLM wrapper around pandas;
# By enforcing privcay we will avoid sending any data to OpenAI.
df = SmartDatalake([df_okta_policies, df_rule_conditions, df_rule_actions,
df_okta_applications, df_access_policies],
config={"llm": llm, "enforce_privacy": True})
Transforming Data for LLM Interaction:
- With our policy data already structured from the Mermaid visualization phase, we’re set to leverage it for LLM querying. This data, residing in our dataframe, represents a rich tapestry of policy information waiting to be explored.
Conversing with AI:
- Armed with queries in natural language, we can now extract meaningful insights from our DataFrame. Imagine asking, “What are the conditions for the default MFA policy?” or “Detail the actions for high-priority sign-on policies.”
- The LLM taps into the DataFrame, interpreting the query, locating the relevant data, and presenting it back in a clear, concise manner. This process is akin to having an intelligent agent dissecting complex policy structures and delivering just what you need to know.
Example Queries
Using the pandasAI library allows us to use natural language to query our data. And as you will see, even if your english is not the best, it returns accurate results.
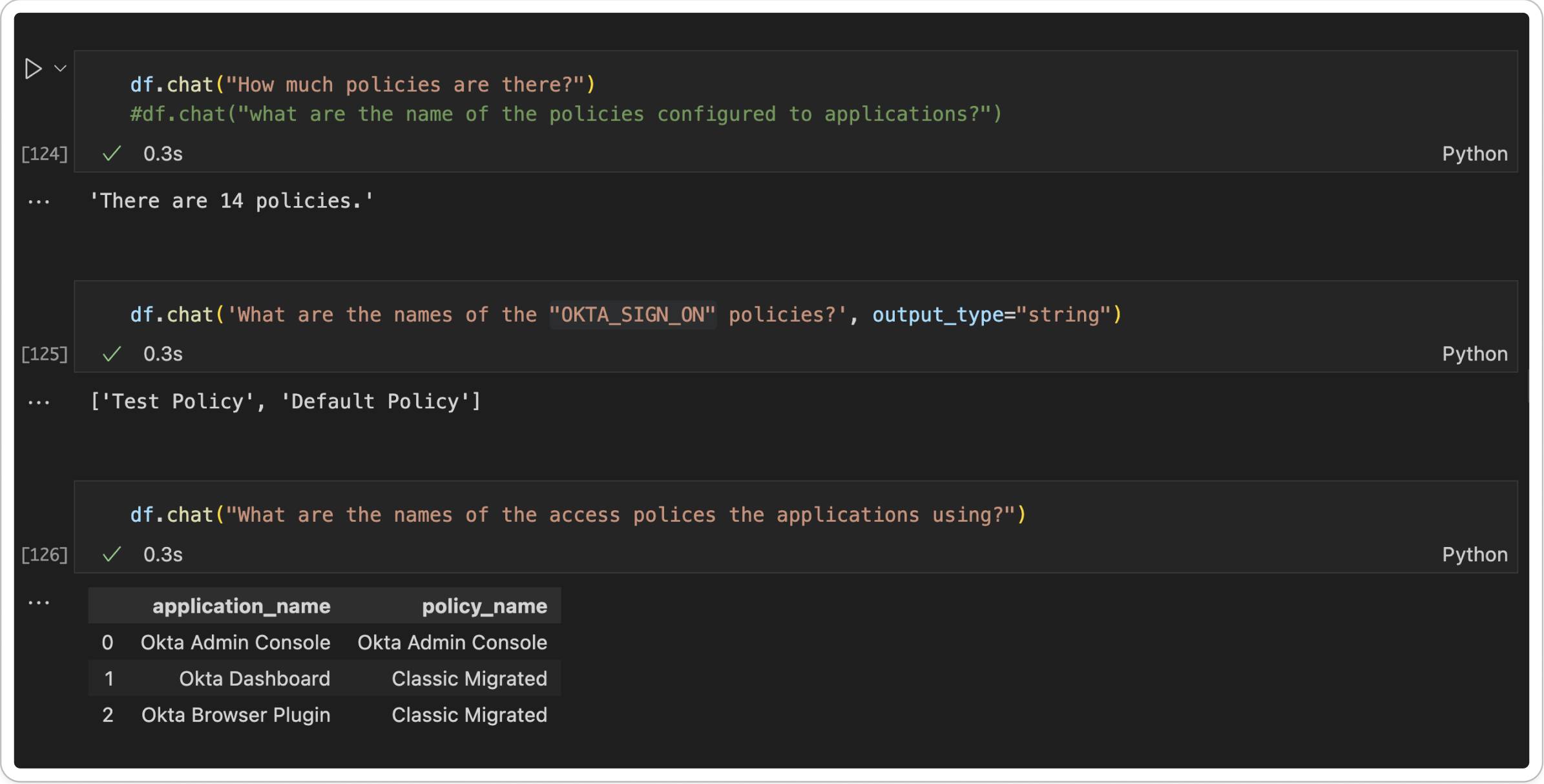
Gleaning Insights:
- This AI-powered approach allows us to unearth nuances and relationships in our policy data that might otherwise be overlooked. It provides a lens to view our policies not just as lines of code or entries in a table, but as dynamic, interactive elements of our security posture.
More Complex Questions
Here is where more focus need to be had, better formatting of the results and exploring the use of prompt templates so we do not have to specify which dataframe to use.
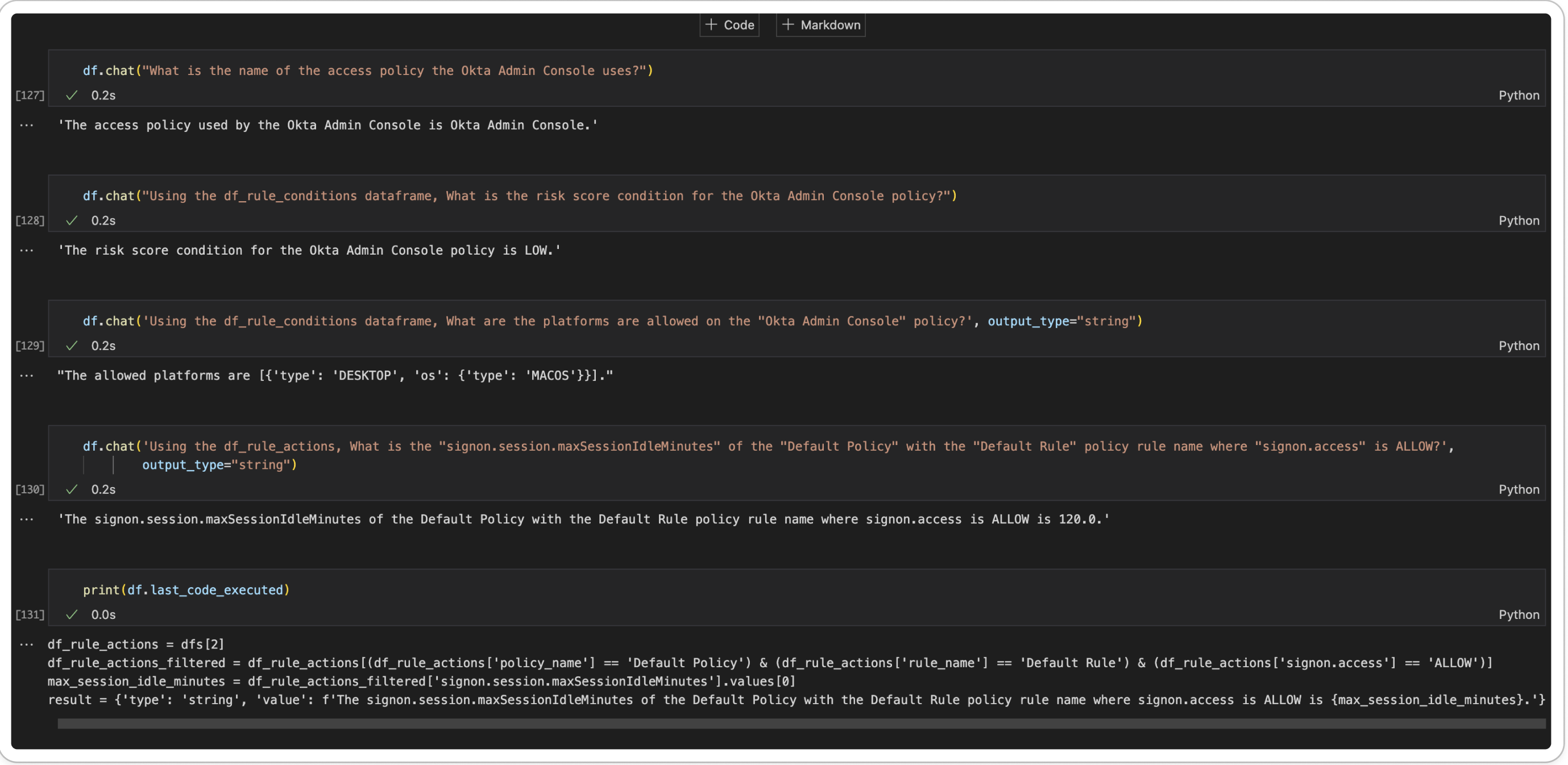
Real-World Application: Automated Policy Insights
Imagine a scenario at CyberTech Inc., a company with a sprawling digital landscape. They’re juggling various Okta policies across multiple departments. Enter our integrated approach: API automation, Mermaid visualization, and LLM querying. With these tools, CyberTech’s IT team embarks on a journey of efficient policy management. One day, a security audit raises concerns about access controls in their remote work policy. Traditionally, this would have meant hours of combing through policy documents. But not anymore. The team queries their LLM: “Show me the sign-on rules for remote employees.” In seconds, they have a clear, visual representation of relevant policies and rules, thanks to Mermaid, and a concise breakdown from the LLM. This rapid access to detailed policy configurations enables them to address the auditor’s concerns and make informed adjustments swiftly.
The Evolution of Policy Management
As we wrap up this exploration, it’s evident that the fusion of API automation, visualization tools like Mermaid, and AI-powered querying with LLMs is more than just a technological advancement; it’s a paradigm shift in policy management. This approach brings clarity, efficiency, and engagement to what was once a labyrinthine task.
Looking ahead, the potential applications of AI in security and identity management are boundless. In my next article, we’ll dive into using Terraform for Change Management of your Okta Policies.
Call to Action: Embracing AI in Policy Management
Call to Action: Embracing AI in Policy Management Now, it’s your turn to embark on this journey. You should experiment with automating your policy documentation, making improvements to the code, and exploring the power of LLMs for data analysis. The future of policy management is not just automated but intelligent and intuitive. In later posts, I will dive into the tools I used in this experiment and explore how you can approach deploying in your environments. Stay curious, stay innovative, and let’s embrace the future of AI in policy management together. 🌐🚀🤖